Tembo’s Blog


Floor Drees
Head of Education
Excitement about the PostgreSQL landscape at the Extensions Ecosystem Summit at PGConf EU
5 min read
Dec 5, 2024

Floor Drees
Head of Education
Rewarding bounties, worth it?
2 min read
Nov 20, 2024


Jason Petersen
Senior Software Engineer
Benchmarking ParadeDB's pg_search: Postgres as your search engine
3 min read
Nov 18, 2024

Floor Drees
Head of Education
Hacking Postgres: Heikki Linnakangas
5 min read
Nov 12, 2024


Nishil Faldu
Software Engineer
Build a Vector Search-Powered E-commerce Platform with Tembo and Zero API Endpoints (and Next.js)
7 min read
Nov 11, 2024

Shaun Thomas
Senior Software Engineer
Plugging the Postgres Upgrade Hole
9 min read
Nov 5, 2024


A. Hendel
Founding Engineer
Llama 3.1-8B-Instruct now available on Tembo Cloud
4 min read
Nov 4, 2024


Darren Baldwin
Engineer
SQL Editor in the Tembo Cloud Dashboard UI
1 min read
Oct 30, 2024

Floor Drees
Head of Education
Hacking Postgres: Francesco Tisiot
4 min read
Oct 22, 2024
Floor Drees
Head of Education
Work on Tembo Open Source for Fun and Profit
2 min read
Oct 17, 2024

Shaun Thomas
Senior Software Engineer
Comparing Columnar to Heap Performance in Postgres with pg_timeseries
5 min read
Oct 10, 2024

Adam Hendel
Founding Engineer
Announcing ParadeDB partnership: Search and Analytics for Postgres
4 min read
Oct 3, 2024


Ry Walker
Founder/CEO
Experience the Full Potential of Tembo Cloud with our Free Trial
2 min read
Oct 3, 2024


Adarsh Shah
Announcing Tembo Self Hosted GA
3 min read
Sep 30, 2024
Jason Petersen
Senior Software Engineer
Using Tembo's Time Series Stack at Home
14 min read
Sep 26, 2024

Adam Hendel
Founding Engineer
Building an image search engine on Postgres
7 min read
Sep 24, 2024


Amy Wong
Head of Marketing
Build on Postgres with Tembo Buildcamp
2 min read
Sep 17, 2024


David E. Wheeler
Principal Architect
What’s New on the PGXN v2 Project
6 min read
Sep 11, 2024

Ry Walker
Founder/CEO
pg_auto_dw: a Postgres extension to build well-formed data warehouses with AI
3 min read
Sep 11, 2024
Adam Hendel
Founding Engineer
Introducing Tembo AI: the simplest way to build AI applications on Postgres
5 min read
Aug 22, 2024
Floor Drees
Head of Education
Tembo Cloud: Now available in a region close to you
2 min read
Aug 13, 2024

Floor Drees
Head of Education
Tembo Cloud now supports Spot instances for cheaper dev instances
2 min read
Aug 6, 2024

Floor Drees
Head of Education
Introducing pause and rename for your Tembo Cloud instances
3 min read
Jul 31, 2024

David E. Wheeler
Principal Architect
To Preload, or Not to Preload
6 min read
Jul 24, 2024

Steven Miller
Founding Engineer
Designing a simple and scalable RBAC system
4 min read
Jul 11, 2024
Ry Walker
Founder/CEO
Announcing Tembo Series A
4 min read
Jul 3, 2024

Steven Miller
Founding Engineer
What you should know about JSON web tokens
5 min read
Jun 24, 2024

Shaun Thomas
Senior Software Engineer
How to Get the Most out of Postgres Memory Settings
18 min read
Jun 10, 2024

Shaun Thomas
Senior Software Engineer
Easier Postgres Management with Alerts on Tembo Cloud
8 min read
May 30, 2024


Ian Stanton
Founding Engineer
Announcing Tembo Self Hosted: Run Tembo in Your Environment
5 min read
May 28, 2024

Steven Miller
Founding Engineer
How Tembo Cloud stores Prometheus metrics data in PostgreSQL
6 min read
May 22, 2024


Samay Sharma
CTO
Introducing pg_timeseries: Open-source time-series extension for PostgreSQL
6 min read
May 20, 2024

Adam Hendel
Founding Engineer
Operationalizing Vector Databases on Postgres
7 min read
Apr 15, 2024

Ian Stanton
Founding Engineer
Advanced PostgreSQL Metrics and Insights on Tembo Cloud with pganalyze
5 min read
Apr 3, 2024

David E. Wheeler
Principal Architect
What’s Happening on the PGXN v2 Project
4 min read
Apr 3, 2024
Adam Hendel
Founding Engineer
Building a Managed Postgres Service in Rust: Part 1
8 min read
Mar 27, 2024

Vinícius Miguel
Software Engineer
Announcing support for Postgres 14 and 16
2 min read
Mar 15, 2024
Steven Miller
Founding Engineer
Announcing Tembo CLI: Infrastructure as code for the Postgres ecosystem
3 min read
Mar 8, 2024
Adam Hendel
Founding Engineer
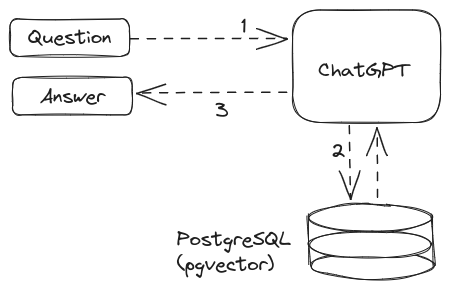
Build a question-answer bot natively using Postgres extensions
5 min read
Mar 5, 2024

David E. Wheeler
Principal Architect
The Jobs to be Done by the Ideal Postgres Extension Ecosystem
6 min read
Feb 21, 2024


Evan Stanton
Software Engineer
MongoDB capabilities on Postgres with Managed FerretDB on Tembo Cloud
5 min read
Feb 15, 2024


Binidxaba
Community contributor
Benchmarking PostgreSQL connection poolers: PgBouncer, PgCat and Supavisor
10 min read
Feb 13, 2024

Evan Stanton
Software Engineer
Simpler Geospatial Workloads on Postgres: An Elephant of a Story
8 min read
Feb 8, 2024

Binidxaba
Community contributor
Pgvector vs Lantern part 2 - The one with parallel indexes
3 min read
Feb 5, 2024
Adam Hendel
Founding Engineer
Automate vector search in Postgres with any Hugging Face transformer
6 min read
Feb 2, 2024

David E. Wheeler
Principal Architect
Presentation: Introduction to the PGXN Architecture
2 min read
Feb 1, 2024

Adam Hendel
Founding Engineer
How we built our customer data warehouse all on Postgres
9 min read
Jan 25, 2024

Samay Sharma
CTO
PGXN creator David Wheeler joins Tembo to strengthen PostgreSQL extension ecosystem
4 min read
Jan 22, 2024

Adam Hendel
Founding Engineer
Build your ML Ops platform on Postgres with Tembo ML
7 min read
Jan 18, 2024
Binidxaba
Community contributor
Benchmarking Postgres Vector Search approaches: Pgvector vs Lantern
6 min read
Jan 17, 2024

Ry Walker
Founder/CEO
Announcing Tembo Cloud GA
3 min read
Jan 10, 2024
Darren Baldwin
Engineer
OLTP on Postgres: 3 Ways the Tembo OLTP Stack Makes Things Simple
3 min read
Jan 5, 2024
Darren Baldwin
Engineer
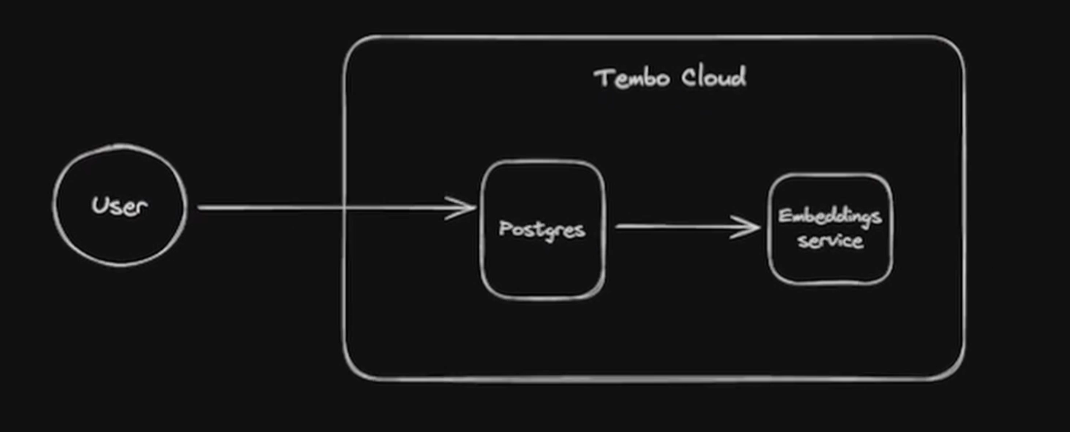
Secure Embeddings in Postgres without the OpenAI Risk
4 min read
Jan 3, 2024

Jay Kothari
Software Engineering Intern
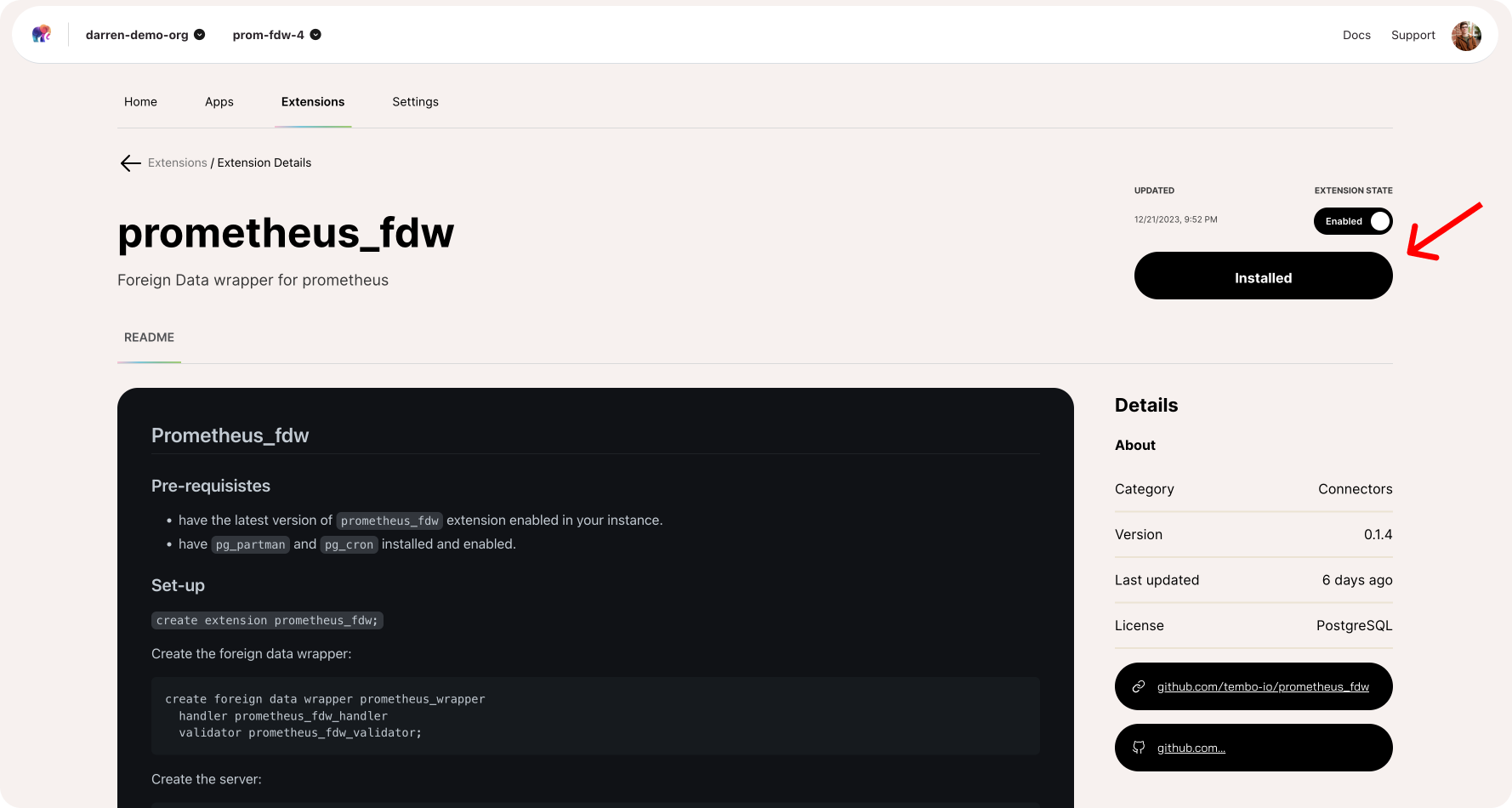
Introducing prometheus_fdw: Seamless Monitoring in Postgres
3 min read
Dec 22, 2023
Darren Baldwin
Engineer
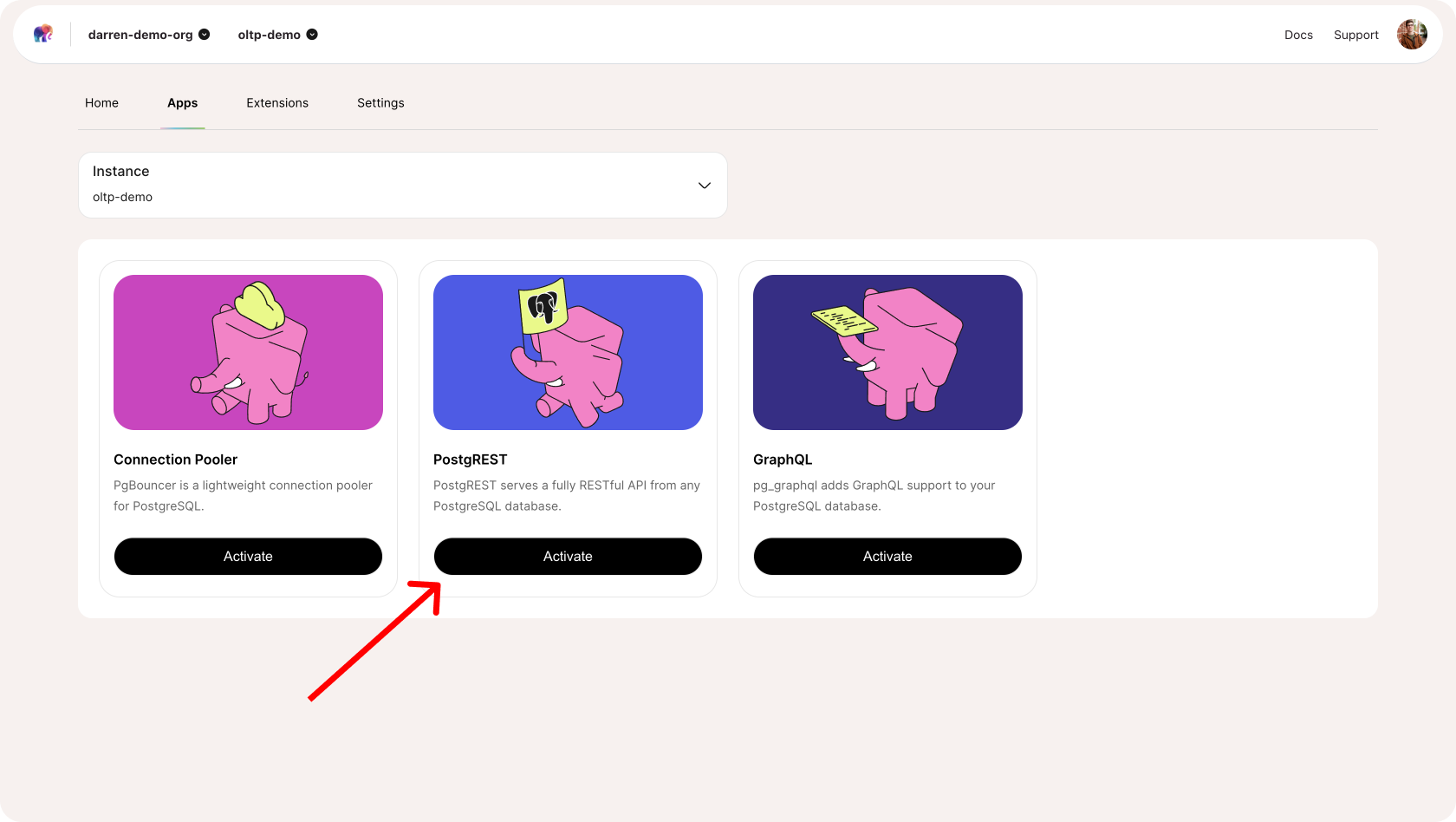
One-Click RESTful APIs in Postgres
3 min read
Dec 21, 2023
Adam Hendel
Founding Engineer
Introducing pg_vectorize: Vector Search in 60 Seconds on Postgres
5 min read
Dec 18, 2023
Ry Walker
Founder/CEO
The Modern Data Stack is a Mess
3 min read
Dec 14, 2023

Adam Hendel
Founding Engineer
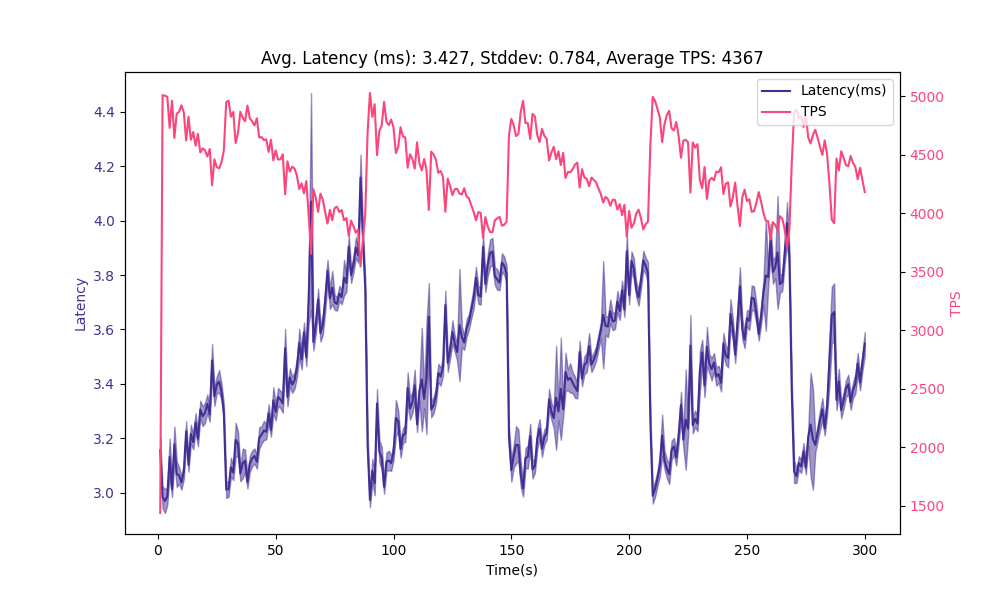
Over 30k messages per second on Postgres with Tembo Message Queue Stack
7 min read
Dec 6, 2023
Ry Walker
Founder/CEO
Hacking Postgres, Ep. 10: Tim Sehn
25 min read
Dec 1, 2023
Ry Walker
Founder/CEO
Hacking Postgres, Ep. 9: Bertrand Drouvot
25 min read
Nov 17, 2023

Binidxaba
Community contributor
Vector Indexes in Postgres using pgvector: IVFFlat vs HNSW
10 min read
Nov 14, 2023

Ry Walker
Founder/CEO
Hacking Postgres, Ep. 8: Philippe Noël
31 min read
Nov 10, 2023

Adam Hendel
Founding Engineer
PGMQ: Lightweight Message Queue on Postgres with No Background Worker
6 min read
Nov 7, 2023

Ry Walker
Founder/CEO
Hacking Postgres Ep. 7: Burak Yucesoy
24 min read
Nov 3, 2023

Adam Hendel
Founding Engineer
Application Services: Helping Postgres Do More, Faster
5 min read
Nov 1, 2023

Ry Walker
Founder/CEO
Hacking Postgres, Ep. 6: Regina Obe and Paul Ramsey
29 min read
Oct 31, 2023
Ian Stanton
Founding Engineer
Tembo Operator: A Rust-based Kubernetes Operator for Postgres
7 min read
Oct 25, 2023

Steven Miller
Founding Engineer
Anonymized dump of your Postgres data
3 min read
Oct 24, 2023

Ry Walker
Founder/CEO
Hacking Postgres, Ep. 5: Alexander Korotkov
23 min read
Oct 23, 2023
Ry Walker
Founder/CEO
Hacking Postgres, Ep. 4: Pavlo Golub
16 min read
Oct 21, 2023

Ry Walker
Founder/CEO
Hacking Postgres, Ep. 3: Eric Ridge
18 min read
Oct 20, 2023
Ry Walker
Founder/CEO
Hacking Postgres, Ep. 2: Adam Hendel
18 min read
Oct 19, 2023
Binidxaba
Community contributor
Unleashing the power of vector embeddings with PostgreSQL
8 min read
Oct 18, 2023
Ry Walker
Founder/CEO
Hacking Postgres Ep. 1: Marco Slot
25 min read
Oct 16, 2023

Adarsh Shah
Introducing Terraform Provider for Tembo
3 min read
Oct 10, 2023
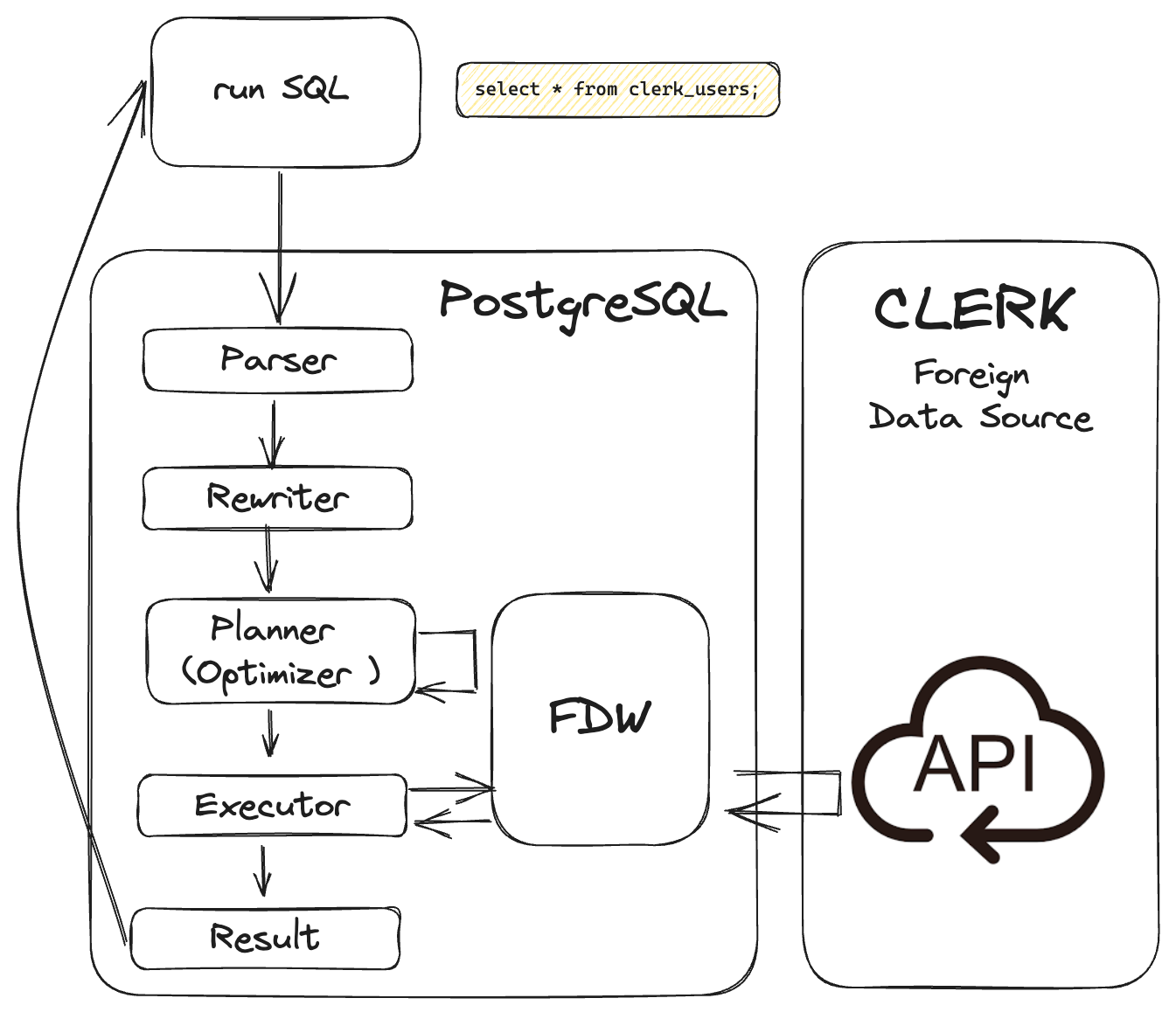
Jay Kothari
Software Engineering Intern
Unlocking value from your Clerk User Management platform with Postgres
5 min read
Oct 3, 2023

Steven Miller
Founding Engineer
Version History and Lifecycle Policies for Postgres Tables
17 min read
Sep 29, 2023
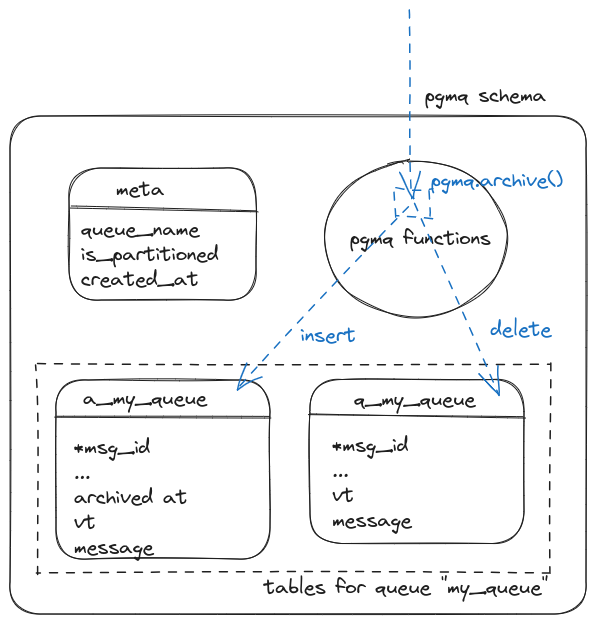
Binidxaba
Community contributor
Anatomy of a Postgres extension written in Rust: pgmq
11 min read
Sep 28, 2023

Samay Sharma
CTO
Postgres 16: The exciting and the unnoticed
9 min read
Sep 20, 2023

Steven Miller
Founding Engineer
Enter the matrix: the four types of Postgres extensions
12 min read
Sep 14, 2023
Samay Sharma
CTO
Tembo Stacks: Making Postgres the Everything Database
5 min read
Sep 6, 2023
Adam Hendel
Founding Engineer
Optimizing Postgres's Autovacuum for High-Churn Tables
10 min read
Aug 31, 2023
Binidxaba
Community contributor
Using pgmq with Python
5 min read
Aug 24, 2023

Adam Hendel
Founding Engineer
Introducing pg_later: Asynchronous Queries for Postgres, Inspired by Snowflake
4 min read
Aug 16, 2023
Adam Hendel
Founding Engineer
Introducing PGMQ: Simple Message Queues built on Postgres
5 min read
Aug 3, 2023

Ry Walker
Founder/CEO
Tembo Manifesto
6 min read
Jul 5, 2023
Ry Walker
Founder/CEO
Introducing Tembo
2 min read
Jan 18, 2023
